Agent OS Claude won my brain shootout for 2026, and the gap was bigger than I expected when I started the test.
I spent six weeks running the same agent OS dashboard with four different brains in the central seat — Claude, GPT, Gemini, and a strong local model — and the differences were night and day.
This post is the honest write-up of what I found, why Claude wins, and where the other brains actually hold up.
I'll walk through the test setup, the four criteria that matter, the head-to-head results, and the verdict for which brain to put in seat one of your own OS.
Want the winning Agent OS Claude template? Inside the AI Profit Boardroom, the OS zip ships with Claude wired in as the brain, plus the prompt library and five weekly coaching calls. Get inside
The Test Setup
Here's how I ran the comparison so you can judge the methodology.
I built the same Agent OS dashboard four times, swapping out the brain in the Intelligence panel each round.
The dashboard kept the same OpenClaw and Hermes layers underneath, the same Obsidian memory feed, the same Claude CLI bridge pattern (adapted to each model's API in the non-Claude rounds).
I ran the same five workflows through each round.
Workflow one was building a 15-source competitor research dossier.
Workflow two was generating a new dashboard panel from a one-paragraph description.
Workflow three was orchestrating a three-tool outreach pipeline.
Workflow four was running a 30-minute scheduled morning briefing job.
Workflow five was a free-form "do this thing" conversation that needed five-plus follow-up clarifications.
I scored each round on four criteria — multi-step reasoning, tool use reliability, code generation quality, and long-context retention.
Same workflows, same scoring rubric, same scoring person (me).
The Four Criteria That Matter For A Brain
Before the results, the criteria.
Criterion one is multi-step reasoning.
Can the brain plan a sequence of 10-15 sub-steps and execute the plan without losing the thread?
This is the difference between a model that can run an agent OS and a model that just produces output.
Criterion two is tool use reliability.
Does the brain call tools cleanly, read the results, integrate them into the next step, and avoid redundant re-calls?
This is what separates orchestrators from chatbots.
Criterion three is code generation quality.
Can the brain ship working code on the first try when you ask it to extend the OS?
The OS keeps growing, so the brain has to be a competent engineer too.
Criterion four is long-context retention.
When the system prompt is 20,000 tokens of vault content plus live agent state, does the brain still pull the right details from early in the context window?
If it can't, the OS gets dumber as the day goes on.
These four criteria are the whole game.
Everything else is a tiebreaker.
Round One — Claude
Claude was the baseline because it's what I run by default, and it set a high bar.
On multi-step reasoning, Claude held the thread through 13 sub-steps on the competitor dossier and produced a clean stitched output.
On tool use, Claude made 47 tool calls across the five workflows with two redundant re-calls — a low error rate.
On code, Claude shipped a working dashboard panel from one paragraph of brief, first try, no manual fixes.
On long context, Claude pulled correct details from token 1,000 of a 22,000-token context at the end of a long session.
Across the rubric, Claude scored a clean A.
This is the brain I run in production.
Round Two — GPT
GPT was the obvious challenger and I came in expecting it to be roughly tied.
On multi-step reasoning, GPT lost the thread around step nine on the dossier and stitched the final output with two missing sub-sections.
On tool use, GPT made 52 tool calls with seven redundant re-calls — meaningfully higher error rate than Claude.
On code, GPT shipped a working panel but it needed two manual fixes before it would run.
On long context, GPT pulled correct details from recent tokens reliably but missed early-context details twice.
GPT scored a strong B+.
It's a great brain.
It's not the best brain for orchestrating an agent OS, because the tool use chain is where the seat really matters and Claude is cleaner there.
If you're already on GPT for everything, you can run an OS with it.
You'll just spend more time fixing redundant calls and re-prompting for missing pieces.
Round Three — Gemini
Gemini has the longest advertised context window of the four, so I expected it to dominate the retention criterion.
On multi-step reasoning, Gemini held the thread through 11 sub-steps before drifting, then re-asked for clarification I'd already given.
On tool use, Gemini made 49 tool calls with five redundant re-calls plus three calls to the wrong tool entirely.
On code, Gemini's panel shipped with three bugs that needed manual fixes.
On long context, Gemini surprised me by missing more early-context details than GPT did, despite the bigger window — the advertised retention didn't hold up in practice.
Gemini scored a B-.
It's a capable model for many things.
It's not the brain I'd pick for an agent OS in 2026.
The tool use sloppiness was the dealbreaker.
Round Four — Strong Local Model
I tested a strong local model — a Llama variant tuned for agentic use — to see if the local route was viable for a privacy-first stack.
On multi-step reasoning, the local model held three sub-steps cleanly before drifting into general restatement of the goal.
On tool use, the local model made 31 tool calls with 11 redundant re-calls and four flat-out wrong tools.
On code, the panel didn't compile.
On long context, the local model couldn't hold the full 22,000-token system prompt at all — it truncated and lost most of the vault content.
The local model scored a C-.
It's perfectly fine for a backup brain when Claude has a service blip, but it can't carry the main load yet.
If privacy is a hard requirement, you can run the local model for sensitive workflows and Claude for everything else.
That's how I have it wired today.
The Comparison Table
Here's the rubric in table form.
| Criterion | Claude | GPT | Gemini | Local |
|---|---|---|---|---|
| Multi-step reasoning | A | B | B- | C |
| Tool use reliability | A | B+ | C+ | D |
| Code generation | A | B | C | F |
| Long context retention | A | B+ | B | D |
| Overall verdict | Production brain | Strong backup | Limited use | Privacy fallback |
The gap between Claude and the others is wider on tool use and code than on raw output quality.
That's the bit that matters most for an agent OS.
Why Claude Wins The Brain Seat
Claude wins because the agent OS seat needs four traits and Claude is the only model that has all four reliably.
It plans long chains without losing the thread.
It calls tools cleanly and integrates results.
It ships working code first try.
It holds enormous context with high retention.
Most models have one or two of those.
Claude has all four.
That's why "agent os claude" is the search query that lands you in the right place if you're picking a brain for your OS this year.
The brand matters and Claude is the brand that earned the seat.
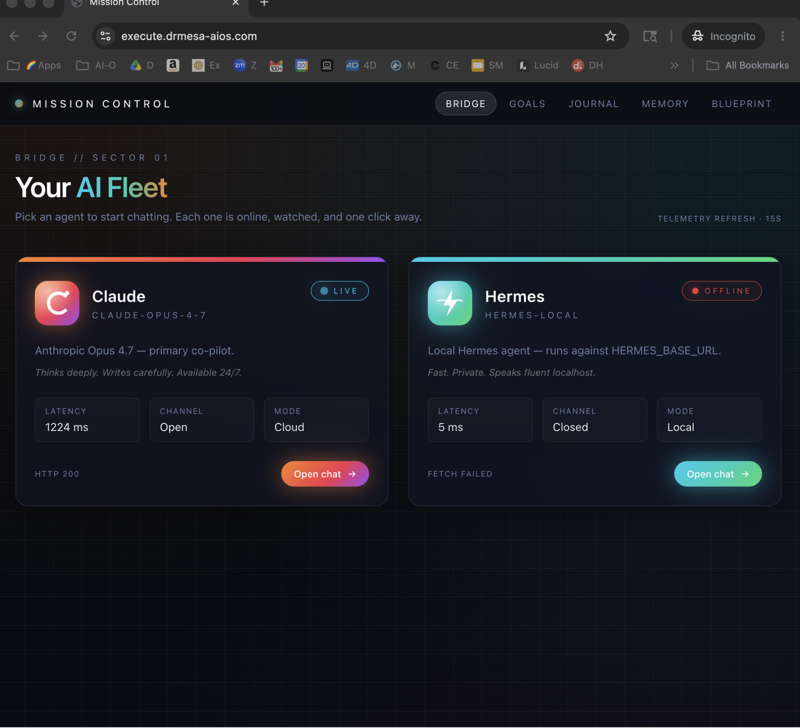
How To Wire Agent OS Claude — The Claude CLI Bridge
The wiring itself is the Claude CLI bridge.
The bridge is a small Node process running locally on your machine.
On one side it talks to the dashboard UI.
On the other side it talks to Claude via the official Claude CLI.
When you type into the Intelligence panel, the dashboard hits the bridge, the bridge calls Claude, Claude streams the response back.
When a scheduled job triggers, the bridge calls Claude in the background and routes the resulting plan to OpenClaw or Hermes.
You see a status pill at the top of the dashboard — connected, busy, or idle — plus a one-click "open control room" button that drops you into the raw CLI for debugging.
The bridge is the piece that turns Claude from a chat window into a service the rest of the OS calls.
Without it, you're back to one-window workflows.
With it, you've got an orchestrator.
The 4-Layer Goldie Mission Stack
For completeness, here's the stack the brain sits inside.
Layer one is Intelligence — Claude Desktop plus Claude Code.
Claude Desktop is the thinking seat.
Claude Code is the typing seat that ships extensions to the OS itself.
Layer two is Execution — OpenClaw, the browser-driving agent.
Layer three is Research — Hermes, the persistent multi-step agent.
Layer four is Self — Obsidian plus OMI, the memory base where everything auto-logs.
Claude orchestrates every layer.
If you want the bridge between Claude and Hermes, my Claude Hermes Agent walkthrough has the MCP wiring.
If you want the OpenClaw side, openclaw-computer-use is the cleanest on-ramp.
How Claude Built Its Own Agent OS Claude Dashboard In One Prompt
The Agent OS Claude dashboard itself was built by Claude Desktop in a single session.
I gave it this prompt verbatim.
Create a beautiful operating system hosted locally for managing
Claude for a website connected to Claude. Should be like a beautiful
mission control dashboard. Then allow me to control my OpenClaw, my
Hermes, and any other agents in separate systems inside the dashboard.
Claude asked four clarifying questions about framework, styling, panels, and hosting.
I answered briefly and Claude built the whole thing in Next.js plus Tailwind running locally on port 3000.
About two hours of Claude time, 15 minutes of mine.
I tried the same prompt with GPT and Gemini to compare.
GPT got close but the build needed more hand-holding and the final dashboard had three broken panels I had to fix manually.
Gemini struggled with framework choice and the build never fully shipped in one session.
That's the practical difference between "Claude as brain" and "GPT or Gemini as brain" — Claude actually finishes the work.
Where The Other Brains Hold Up
I want to be fair to the non-Claude brains because they all have real use cases inside the same stack.
GPT is excellent for one-shot creative work — copy, naming, brainstorms.
If you've got a workflow that's a single call with a clear deliverable, GPT often wins on raw output quality.
Gemini is excellent for long-document reading.
When I need to feed the OS a 200-page PDF and ask for a structured summary, Gemini sometimes pulls cleaner details than Claude.
Local models are excellent as backup brains.
When Claude has a service blip or when a workflow has to stay on-prem, having a local fallback wired in saves the day.
The right answer isn't "use Claude for everything" — it's "use Claude as the brain in seat one and slot the others in as specialists where they shine."
The Cost Picture
Cost matters for this comparison too, so here's the practical view.
Running Claude as the brain costs roughly $50-80 a month for a single founder, including Claude Pro for the chat layer and API credits for the background jobs.
Running GPT in the same seat costs about the same — pricing parity is now close enough that cost isn't a deciding factor.
Running Gemini in the seat costs slightly less, especially if you're already paying for Google's ecosystem.
Running a local model in the seat costs nothing for tokens but you'll spend on a machine with enough VRAM to run a strong model, which is meaningful upfront.
Cost shouldn't pick the brain.
Capability should.
That's why I run Claude.
The Vimeo Walkthrough Of The Boardroom
If you want to see what's inside the boardroom that ships the Claude-wired OS template, this is the walkthrough.
Want the winning stack ready to run? The AI Profit Boardroom ships with the Agent OS Claude zip pre-wired with Claude as the brain — plus the prompt library and five weekly coaching calls. Join here
What I'd Pick If I Was Starting Today
If I was starting from scratch today, here's the exact stack I'd build.
Claude in seat one as the orchestrator brain.
Claude Code as the build hand for OS extensions.
OpenClaw on the browser layer for anything interactive.
Hermes on the research layer for anything scheduled or long-running.
Obsidian plus OMI on the Self layer for memory.
GPT slotted in as a specialist for one-shot creative work where it wins.
Local model wired as a backup brain for service blips or sensitive workflows.
That's the stack I run today and it's the stack the boardroom ships in the template.
Free Backup Plan If You Don't Want To Pay Yet
If you can't commit to Claude Pro yet, here's the free starting path.
Build the OS with Claude Desktop's free tier and accept the slower response times.
Wire the bridge to a free Hermes setup and a free OpenClaw setup.
Get the dashboard running locally with no cost.
Once you see the leverage, upgrade to Claude Pro and watch the speed and quality jump.
That's how I'd onboard a founder who's cautious about subscription cost — get the value visible, then scale up.
FAQ — Agent OS Claude vs Other Brains
Is Claude really better than GPT for an Agent OS brain?
In my six-week head-to-head test, Claude scored an A across all four criteria and GPT scored a B+ — close in raw output but meaningfully cleaner on tool use and orchestration.
Can I run Agent OS Claude with Gemini instead?
You can, but Gemini's tool use sloppiness and weaker code generation make it a B- option compared to Claude's A in the same seat.
What about local models as the brain?
Local models are great backup brains for privacy or service blips but they can't carry the main orchestration load in 2026 — score them as fallback, not primary.
Is the Claude CLI bridge required?
For the cleanest dashboard experience, yes — the bridge handles streaming, auth, and reconnects properly, which direct API calls don't.
Can I switch brains later if I start with one and want to change?
Yes — the Intelligence layer is modular and swapping the brain is mostly a config change, though re-tuning prompts for the new brain takes a day.
How long does the brain comparison test take to run yourself?
If you build the OS once and just swap the API config between models, you can run the full five-workflow comparison in a long weekend.
About Julian
I'm Julian Goldie, AI entrepreneur, SEO expert, and founder of the AI Profit Boardroom with 3,000+ members.
I help business owners scale with AI agents, automation, and SEO.
- 400K+ YouTube subscribers
- 7-figure AI agency (Goldie Agency)
- Daily training inside the Boardroom
- Author of multiple AI automation playbooks
Get my best AI training inside the AI Profit Boardroom
Latest Updates
- Agent OS — the parent OS pattern guide.
- AI Agent OS — the broader category context.
- Agent OS Hermes — the Hermes-first stack.
Further Reading On Agent OS Guide
For deeper walkthroughs on the topics in this article, the Agent OS Guide library has these worth bookmarking.
- Agent OS Guide — the full library of Claude-first agent OS walkthroughs in one place.
- How Claude Mythos Changed AI — context on why Claude sits at the centre of this stack.
- Free Claude Code Setup Guide — the no-cost path to running Claude Code locally.
- Hermes Agent OS Q&A — common questions when pairing Claude with Hermes.
Also On Our Network
- Read on bestaiagentcommunity.com
- Read on aiprofitboardroom.com
- Read on juliangoldieaiautomation.com
- Read on aisuccesslabjuliangoldie.com
Related Reading
- What is Agent OS — the plain-English overview.
- Agentic AI OS — the agentic flavour.
- Claude Hermes Agent — bridging Claude to Hermes.
- Hermes Agent OS — the Hermes-first OS view.
- OpenClaw Computer Use — the browser layer.
Video notes + links to the tools
Get a FREE AI Course + Community + 1,000 AI Agents
If you only test one brain in seat one of your operating system this year, make it Claude — the head-to-head says agent os claude is the configuration that wins.